There is lots of literature on instruction pipelines in CPUs, but GPUs remain poorly understood. GPUs execute instructions in a wildly different manner, and many common compiler transformations that are effective for CPUs – such as strength reduction, or partial dead code elimination – can actually hurt GPU performance. Through the lens of NVidia’s latest series of GPUs, let’s take a look at how instructions are actually executed and how that affects us as programmers and compiler developers.
The NVidia GP100
The latest GPU from NVidia is downright impressive. Each GPU contains 56 SMs, each capable of issuing 4 warp-instructions per cycle, for a monstrous theoretical 7168 instructions per cycle. This theoretical limit is sadly, not reachable due to a relatively meager set of functional units behind the massive pipeline front-end. Each SM is divided into 2 symmetric halves, each containing 2 warp dispatchers, 8 memory load/store units, 16 double-precision floating-point units, 8 special function units (SFUs), and 32 general-purpose cores. Due to unit saturation, the actual maximum IPC is only 5376.
So why set up a GPU this way? The answer lies in the architecture, which can only rarely push instructions maximally through the front of the pipeline. Previous CUDA architectures often left many functional units idle, so the Pascal architecture reduced their number, instead adding additional SMs.
Mapping the Grid
Before we can discuss instruction execution, we need to understand what happens when a CUDA kernel is invoked. When you invoke a kernel such as kernel<<<gridDim, threadDim, sMem, stream>>>(d_ptr), the following things happen:
- If the stream provided is a blocking stream, we will wait for the stream to become idle before continuing
- The CUDA binary is selected as follows:
- If there is a cached binary for this kernel and compute architecture on the GPU, it is used.
- If there is a binary included in the executable for this kernel and compute architecture, it is sent to the GPU cache, and used.
- If there is PTX for this kernel in the executable, it is assembled by the CUDA runtime into a binary, sent to the GPU cache, and used.
- A compute work-unit is appended to the work queue for each unique grid index in gridDim
- Streaming Multiprocessors (SMs) each accept up work units until a resource limit is hit. Possible limits include number of threads(2048), blocks(32), registers(65536), or available shared memory(64K).
- The Streaming Multiprocessor assigns all required resources for all accepted threads, including registers and shared memory assignments. This allows for zero-overhead context switching, used later.
The Pascal Pipeline
At this point, each SM is ready to execute instructions. SMs manage threads in warps of 32, and decode/issue/execute those groups simultaneously.
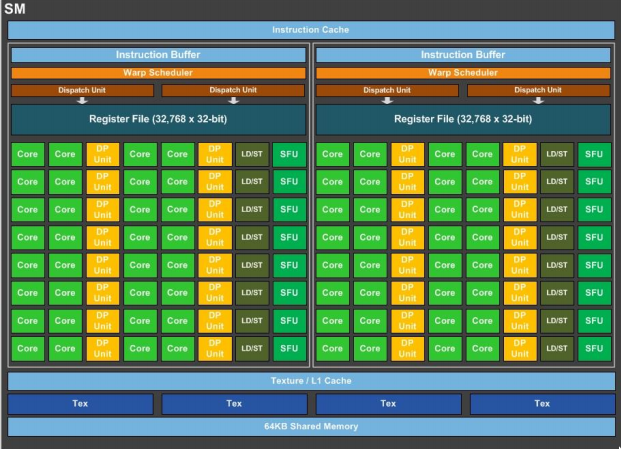
Instructions flow down through the instruction cache, to the instruction buffer, are scheduled to a dispatch unit, which then executes in the appropriate CUDA core for the instruction. Similarly to many modern CPUs, Pascal GPUs contain a dedicated instruction cache, with extremely high hit rate. Unlike CPUs, when there is an instruction cache miss, the latency can often be hidden by other instructions already present in the instruction buffer.
The instruction buffer is where the SM first partitions. At initialization time, threads are assigned to one half of the SM or the other. NVidia has never published exactly how this split is done, but we can assume something simple like even/odd warp IDs is used. The instruction buffer does not just hold instructions, but rather (instruction, warpID, threadMask) tuples. The warpID is used to calculate the offset into the register file for each thread within the warp, and the threadMask is used to specify threads that should not execute the current instruction. Within the instruction buffer, entries are divided into ready and not-ready sets, where instructions in the ready set have all data available and are ready for execution.
For the moment, let’s step over the warp scheduler. It’s important, and we’ll get back to it, but we need to understand some other parts first. Let’s talk about dispatch. The dispatcher is responsible for ensuring threads get executed. It takes the given instruction, the warp ID, and the thread mask, and calculates the thread IDs that will actually execute the instruction. Using these thread IDs, it calculates absolute register addresses for each thread. Then, the dispatcher sends each thread-instruction to a free, applicable functional unit. If there are insufficient functional units, then the dispatch will queue the remaining thread-instructions for the following cycle.
So what do we have for functional units? The pascal architecture defines 4 different types of addressable functional unit: Load/Store memory units, Double precision floating-point units, Special functional units (used for approximate transcendental functions, such as sqrt, sin, etc), and “cores”, responsible for all remaining operations.
It’s at this point we reach the Warp Scheduler. The job of the warp scheduler is simple: Each cycle, try to fill both dispatch units. If you can’t, then stall one or both dispatch units. Complicating this job are a some requirements: 1. Sometimes, one or both of the dispatch units will still be busy. 1. Don’t dispatch an instruction that we have no free functional units for. 1. If we dispatch 2 instructions, they must come from the same warp.
Each cycle, the warp scheduler recieves the number of available functional units, and the number of free dispatchers, as well as the instructions in the ready set. If both dispatchers are free, the warp scheduler preferentially selects a pair of sequential independent warp instructions. (Assuming both instructions have some free functional units) Failing that, it will stall one of the dispatchers, and selects an instruction with functional units available. Notably, the warp scheduler does not attempt to maximize functional unit usage.
So far, we’ve discussed how thread masks are used, but not how they are generated. Thread masks are generated by CUDA cores when a conditional branch is executed, and threads within the warp evaluate the conditions differently. You can imagine a stack of thread masks, where each subsequent divergent condition produces an additional thread-mask in the set. When some threads in a warp take a conditional branch, a mask is generated and put on top of the stack, executing the not-taken branch first. Masked execution continues until a compiler-injected merge point is reached. Then, the complement of the mask is generated and execution begins again from the taken branch target. When the merge point is reached again, the mask is popped off the stack.
Key Differences from CPUs
Some of the above sounds a little bit odd, but it’s worth pointing out how this system differs from traditional CPUs. The key idea behind the GPU architecture is clear: We don’t care about instruction latency. GPUs can execute an instruction from any thread, and each functional unit is fully pipelined (within reason, the memory subsystem has a finite request buffer). This means GPUs don’t have to wait for an instruction to complete before moving on, they just do something else while they wait. As long as there’s other work to be done, the GPU is working.
Pascal GPUs do not attempt to do register renaming, or pass results backwards. There’s no branch prediction, and most of the addressable functional units are multipurpose, to reduce the required complexity on the warp scheduler and dispatcher. Memory access is SLOW, with cache hit times upwards of 50 cycles, and cache misses climbing above 500 cycles. The goal of the GPU is to always be doing something else to hide latency, rather than trying to reduce it.
Takeaways
Aside from learning about a downright odd computing architecture, I hope you take some things away from this post. Here’s what I learned while writing this:
- In order to write performant code on the Pascal GPUs, the level of both thread-level and block-level parallelism must be extremely high.
- Branch divergence within a warp can halve performance because of the need to travel both paths, but phrasing the problem as arithmetic may not help if it uses more functional units.
- Using instructions that target previously unused functional units can actually unlock hidden additional performance
- Even as GPUs emphasize massive thread-level parallelism, instruction-level parallelism is still required for full performance.
If you made it this far, you’re probably way too interested in GPU architecture. I hope you learned something! Feel free to comment below, or subscribe to my RSS feed. Thanks!